![France's La Poste DDoS Attack: What Happened & How to Protect Your Business [2025]](https://tryrunable.com/blog/france-s-la-poste-ddos-attack-what-happened-how-to-protect-y/image-1-1766586239256.jpg)
France's La Poste DDoS Attack: A Wake-Up Call for Critical Infrastructure
It's Monday morning in France. Thousands of people are trying to check their bank balances, pay bills, send packages. Nothing works. La Poste, the country's national postal service and one of Europe's oldest financial institutions, is completely offline.
This isn't some small startup getting hit. This is critical infrastructure. This is the backbone of how millions of French citizens interact with financial services, government communications, and postal logistics. And it's down.
On the surface, the incident looked straightforward: a "major network incident" that knocked multiple services offline simultaneously. But beneath the surface, it raised serious questions about infrastructure resilience, cyber defense priorities, and what actually happens when essential services fail. The incident also highlighted a crucial gap in how organizations communicate during crisis situations. Within hours, local media outlets were reporting conflicting information about whether this was a ransomware attack or a distributed denial of service (DDoS) assault. La Poste itself remained vague, while independent analysts reviewed traffic data trying to piece together what actually happened.
For cybersecurity professionals, IT directors, and anyone responsible for critical systems, this incident serves as a stark reminder. If it can happen to a major European postal service with dedicated security teams, it can happen to anyone. The question isn't whether your organization will face an attack like this. The question is whether you're prepared.
Let's break down exactly what happened, why it matters, and most importantly, how you can make sure your systems don't suffer the same fate.
TL; DR
- Massive Infrastructure Outage: La Poste experienced complete service disruption affecting online banking, postal services, and digital identity systems during peak business hours
- Attack Type Unclear: While suspected to be a DDoS attack, the true nature remained ambiguous, highlighting communication gaps during critical incidents
- Partial Service Continuity: Banking customers could still conduct transactions via SMS authentication, ATMs, and in-person counter services
- Supply Chain Vulnerability: The incident exposed how critical infrastructure dependencies create systemic risk across entire economies
- Detection Challenges: Even sophisticated monitoring tools showed only minor traffic anomalies, making attribution difficult

Investing
What Exactly Happened at La Poste?
Let's start with the facts. On a Monday morning, France's La Poste announced a "major network incident" via their Facebook page. Within minutes, multiple services went dark:
The laposte.fr website showed only a single message: "Our website is unavailable." The La Banque Postale mobile app stopped responding. Digiposte (their digital document management service) went offline. The La Poste Digital Identity system, which handles authentication for government services, became inaccessible. For millions of users, the entire digital ecosystem simply vanished.
But here's where it gets interesting. Not everything stopped. This is actually a crucial detail that tells us something important about how the attack worked.
Banking customers could still execute transactions if they had SMS authentication enabled. Cash withdrawals at ATMs continued uninterrupted. Point-of-sale card payments at retail locations remained functional. WERO (a European payment system) transfers still processed. In-person counter services at physical post offices continued operating normally.
This pattern is significant. If this were a complete infrastructure meltdown or ransomware attack that encrypted core systems, you'd expect those payment systems to go down too. Instead, we see a surgical strike against online services while underlying transaction systems remained operational.
La Poste's official statement was remarkably terse. They said the incident was a "major network incident" but provided no technical details about the root cause, timeline of impact, or recovery efforts. This lack of transparency would become a pattern. As hours passed, information vacuum was filled by local media speculation.
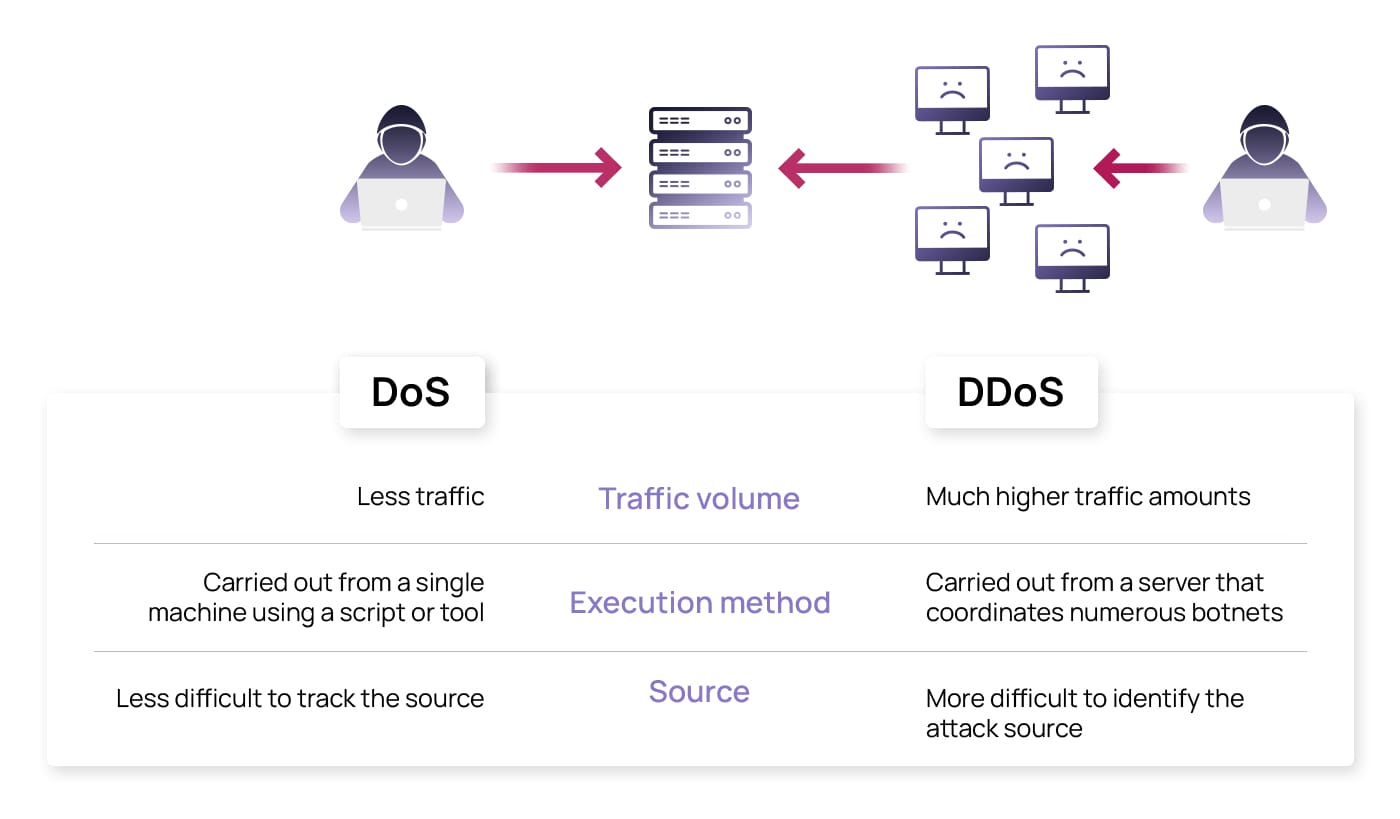
By late Monday, Le Monde Informatique, a respected French tech publication, reported that local sources suggested this was a Distributed Denial of Service (DDoS) attack rather than ransomware. This distinction matters enormously. DDoS attacks overwhelm systems with traffic. Ransomware encrypts data and threatens to leak it. They're fundamentally different attack types with completely different remediation strategies.
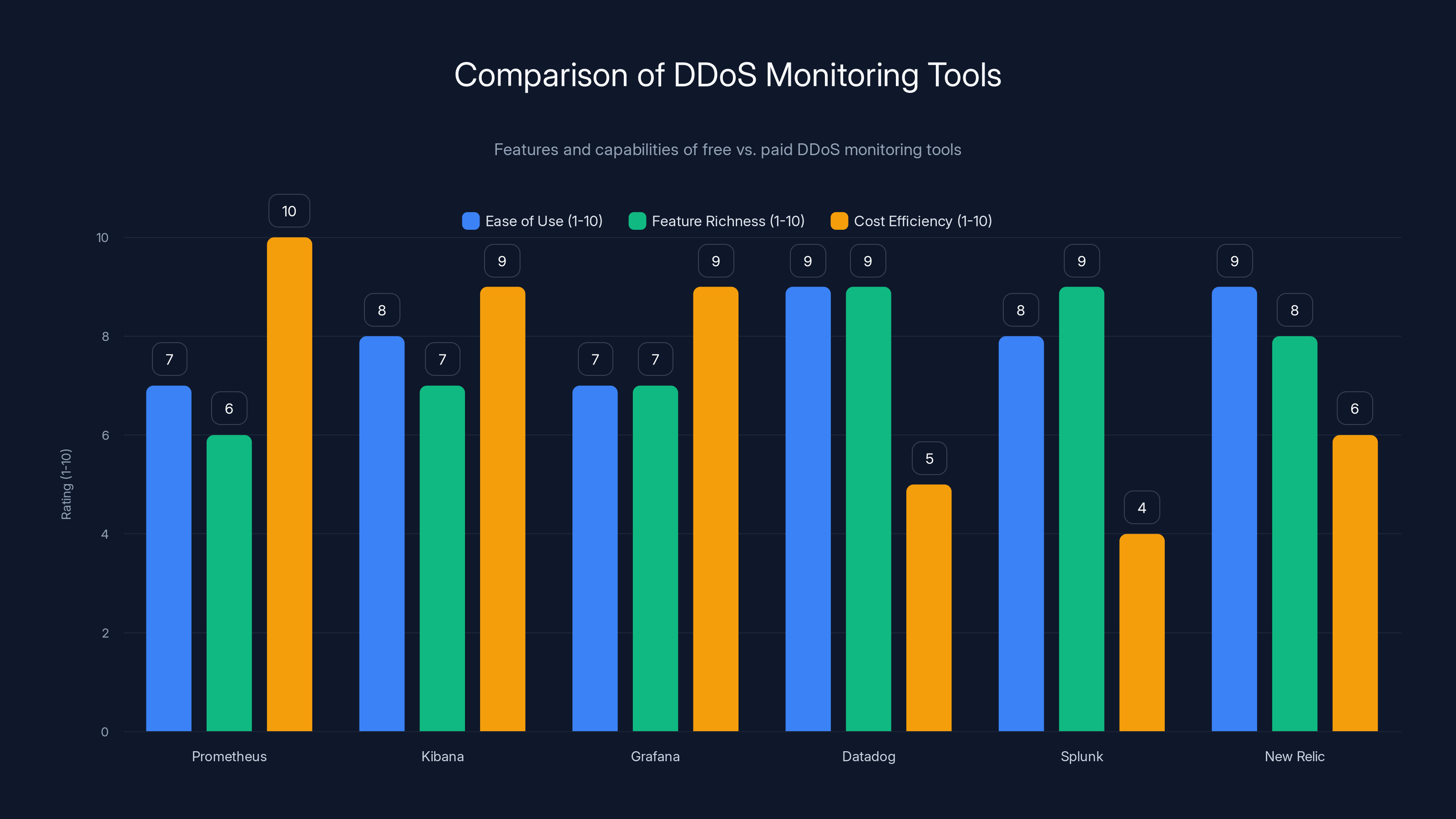
This chart compares free and paid DDoS monitoring tools based on ease of use, feature richness, and cost efficiency. Free tools like Prometheus and Grafana score high on cost efficiency, while paid tools like Datadog and Splunk offer more features.
The Attack Type Question: DDoS vs. Ransomware
Here's where the story becomes murky. La Poste never officially confirmed the attack type. Local media suggested DDoS. But independent security analysts looking at Cloudflare Radar (a service that tracks global traffic patterns and DDoS activity) found something unexpected: only "minor traffic spikes," not the massive volume you'd typically see with a large-scale DDoS attack.
This discrepancy matters. If this was a DDoS attack, it was either extremely targeted, using sophisticated techniques that distribute traffic in unusual patterns, or it wasn't a traditional volumetric DDoS attack at all.
Let's think about the mechanics of each attack type:
DDoS Attacks flood a target with traffic from many sources simultaneously. A basic volumetric DDoS might send millions of requests per second, each one consuming bandwidth or server resources. Network monitoring tools typically catch these because they show massive traffic volume on the target's inbound connections. The Cloudflare Radar finding of only "minor traffic spikes" makes a traditional DDoS explanation problematic.
Ransomware Attacks involve gaining unauthorized access to systems, then encrypting data and demanding payment. Ransomware doesn't necessarily show up as unusual network traffic. It's often deployed quietly over weeks before activation. If an attacker had access to La Poste's network and deployed ransomware, it might knock services offline without generating the traffic signature you'd see with DDoS.
Advanced DDoS Techniques exist that don't require massive traffic volume. These include:
- Application-layer attacks that target specific functionality rather than flooding bandwidth
- Slowloris attacks that exhaust connection limits with minimal traffic
- DNS amplification that uses small requests to generate large responses
- Protocol exploitation that crashes services without volume
Given the limited traffic detected, if this was DDoS, it was likely sophisticated. If it was ransomware, the traffic silence makes perfect sense.
The Timeline: When Did Things Break?
Monday morning. Peak business hours. This timing wasn't random. Critical infrastructure attacks often target peak hours because that's when impact is maximum and detection response times are typically slower (more noise in the system).
La Poste's network team likely detected the issue within minutes. Customers immediately reported problems. Social media filled with complaints. By afternoon, major news outlets picked it up. Yet official communication remained minimal.
The lack of clear timeline information is frustrating from a technical perspective. When exactly did services go offline? How long was each service unavailable? Did different services recover at different times? Were there cascading failures? None of these details were publicly disclosed.
This information vacuum creates problems:
- Customers can't plan: If you don't know when service will return, you can't make alternative arrangements
- Analysts can't learn: Without timeline data, we can't understand attack progression
- Trust erodes: Silence during crisis breeds speculation and anxiety
- Competitors can't prepare: Other organizations can't learn from publicly disclosed timelines
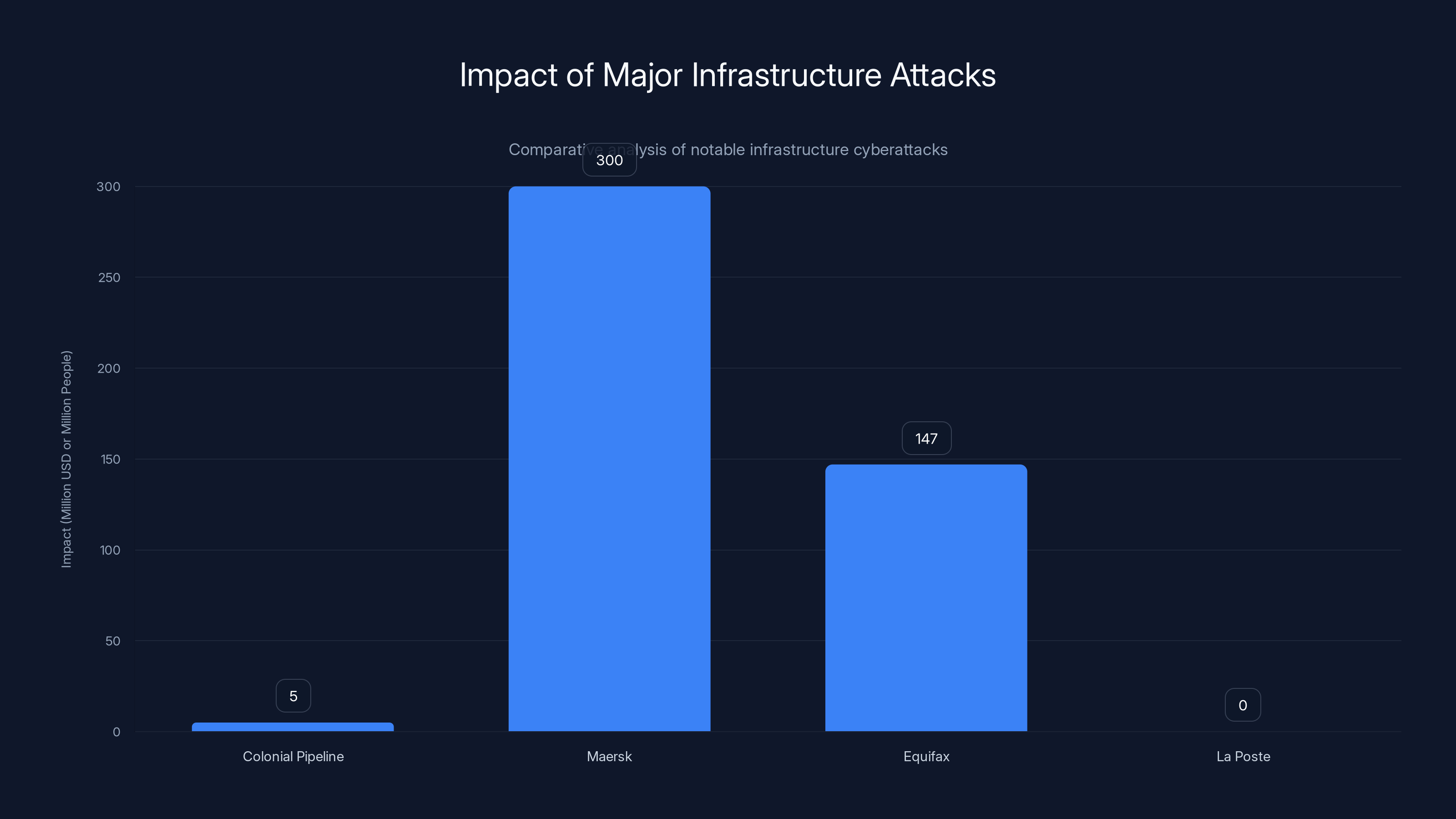
This chart compares the impact of major infrastructure attacks, highlighting the potential systemic risk posed by cyberattacks on critical infrastructure. Estimated data for La Poste based on narrative context.
Why This Matters: Critical Infrastructure Under Siege
La Poste isn't just any company. It's critical infrastructure. Here's why that distinction is important:
3.2 million people use La Banque Postale for banking services. That's roughly 5% of France's entire population with their money in this system. Many are elderly customers who've banked there for decades and don't switch easily.
400+ million packages moved through La Poste annually. Logistics depend on this system. Businesses rely on it.
Government services integrate with La Poste's digital identity system. When it's offline, citizens can't access certain government services.
This creates a domino effect. One organization goes down, and suddenly the impact radiates outward to their customers' customers, to supply chains, to government services. This is what cybersecurity experts call "systemic risk."
For comparison, consider the impact of other major infrastructure attacks:
- When the Colonial Pipeline was hit by ransomware in 2021, fuel shortages cascaded across the U.S. East Coast within hours
- When Maersk's shipping systems were attacked in 2017, their costs jumped $300 million in a single quarter
- When Equifax was breached in 2017, 147 million people had their personal information compromised
La Poste's incident, while serious, at least maintained some functionality. Banking continued for customers with SMS authentication. Physical counter services worked. But what if the attackers had deployed deeper, more destructive payloads?
The Supply Chain Vulnerability Angle
Here's something most people miss when analyzing this incident: La Poste didn't build all of its infrastructure alone. Modern critical infrastructure relies on complex supply chains of vendors, cloud providers, software makers, and infrastructure partners.
When one system goes down, was it:
- A direct attack on La Poste's systems?
- An attack on a vendor that La Poste depends on?
- Compromised third-party software running on La Poste's infrastructure?
- A misconfiguration that exposed La Poste to indirect attack?
None of these details were disclosed. But the supply chain angle is crucial because it means the risk extends far beyond La Poste's own infrastructure teams.
According to the 2024 Verizon Data Breach Investigations Report, 62% of breaches involved a third-party or supply chain compromise. In other words, most successful attacks don't directly compromise the target. They compromise something the target trusts.
For La Poste, this could mean:
- A compromised employee's credentials from a vendor
- Malware in software from a trusted IT partner
- Misconfigured access controls that allowed lateral movement from partner systems
- Vulnerable APIs connecting to trusted third parties
This is why executives at banks, utilities, governments, and large enterprises now obsess over "third-party risk management." You can have perfect security on your own systems, but if a vendor has poor security, they become your vulnerability.

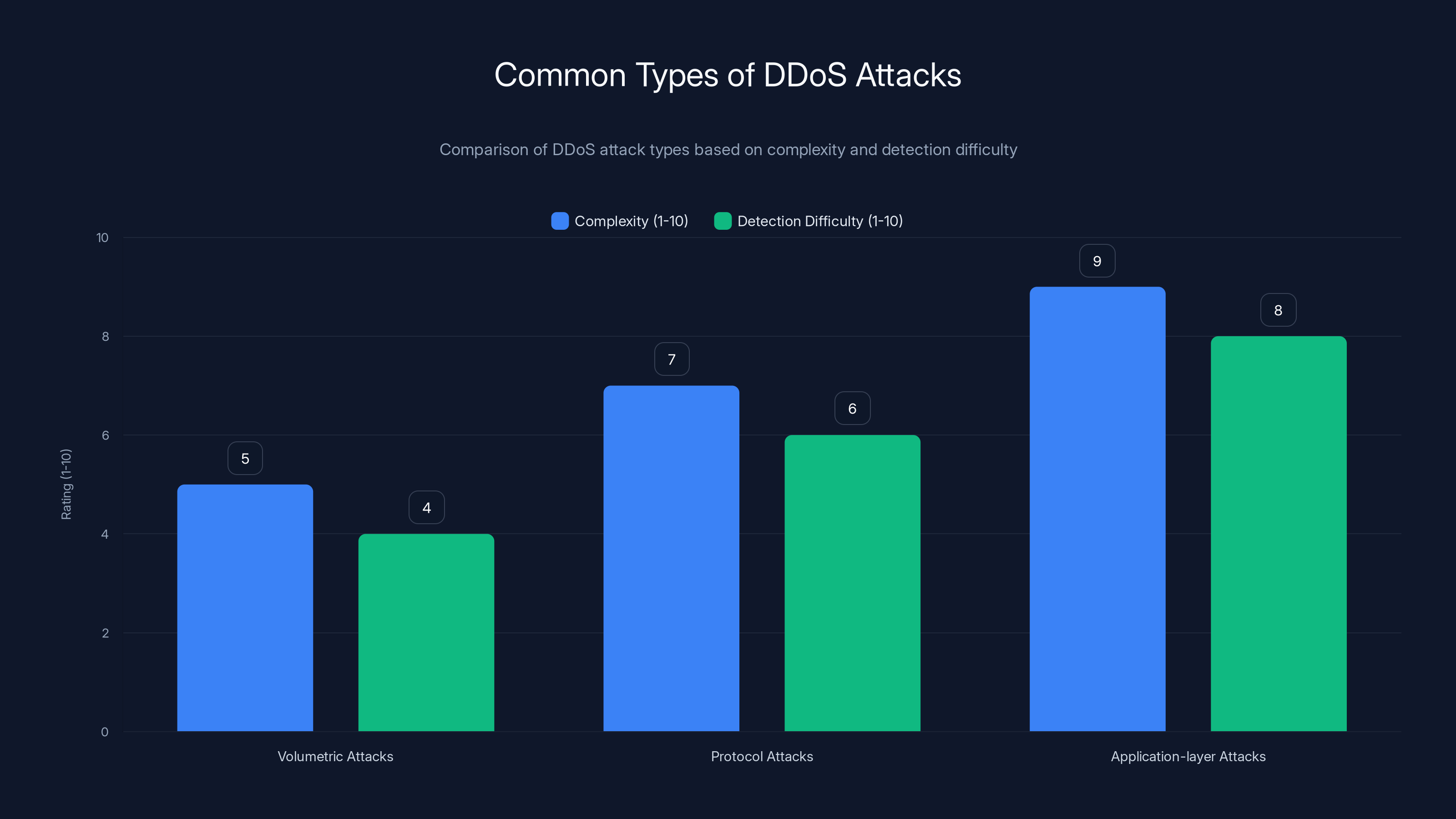
Application-layer attacks are the most complex and hardest to detect, with a complexity rating of 9 and detection difficulty of 8. Estimated data.
Detection Challenges: Why Monitoring Failed
Here's an uncomfortable truth: the tools that La Poste presumably had in place didn't reliably detect what was happening. The Cloudflare Radar data showing only "minor traffic spikes" tells us something important about modern attack sophistication.
Basic monitoring catches basic attacks. Attackers know this. So sophisticated actors develop techniques that defeat basic monitoring:
Slow, Distributed Attacks that spread load across many sources so no single source looks anomalous. Imagine 50,000 servers each making just 10 requests per second. Total impact might be massive, but no single data point looks suspicious.
Application-Layer Attacks that target specific functions rather than bandwidth. A database query that's expensive to compute gets repeated. From a network perspective, it looks normal. From a database perspective, the system is melting.
Legitimate-Looking Traffic that exploits business logic rather than overwhelming capacity. An attacker might repeatedly initiate legitimate transactions that are computationally expensive to process, looking exactly like real customer activity.
Encrypted Traffic that hides the attack pattern. If attackers use HTTPS (encrypted), network monitors can't see the actual requests, only that a lot of traffic is flowing.
This is why modern infrastructure requires behavioral monitoring beyond just traffic analysis. You need:
- Anomaly detection that understands your normal patterns, then flags deviations
- Application performance monitoring that tracks database queries, API responses, and compute usage
- Log analysis that correlates events across systems
- Threat intelligence that understands attacker tactics and tools
Standalone traffic monitoring at the network edge is no longer sufficient.

The Communication Breakdown
Maybe the most instructive aspect of the La Poste incident is how poorly information flowed.
La Poste's official statement was sparse and vague. Customers learned about the extent of the outage from Twitter/X, Reddit, and messaging apps before La Poste confirmed details. Local media filled gaps with speculation.
Compare this to how leading organizations now handle outages:
AWS publishes real-time status pages that update every 15 minutes during incidents. Customers know exactly which services are affected, what the issue is, and when recovery is expected.
GitHub releases incident post-mortems publicly within days of major outages, explaining exactly what happened, why, and what they'll change.
Microsoft provides detailed incident reports after major service disruptions.
These companies understand something La Poste clearly didn't: transparency during crisis reduces panic and builds trust.
When organizations stay silent, humans fill the vacuum with speculation. Speculation often assumes the worst. Panic follows.
If La Poste had been transparent—"We detected unusual traffic patterns at 9:47 AM. Our incident response team was activated. We're working to isolate affected systems. We'll provide updates every 30 minutes"—the narrative would be different.
Instead, silence created speculation. Speculation created confusion. Confusion created distrust.

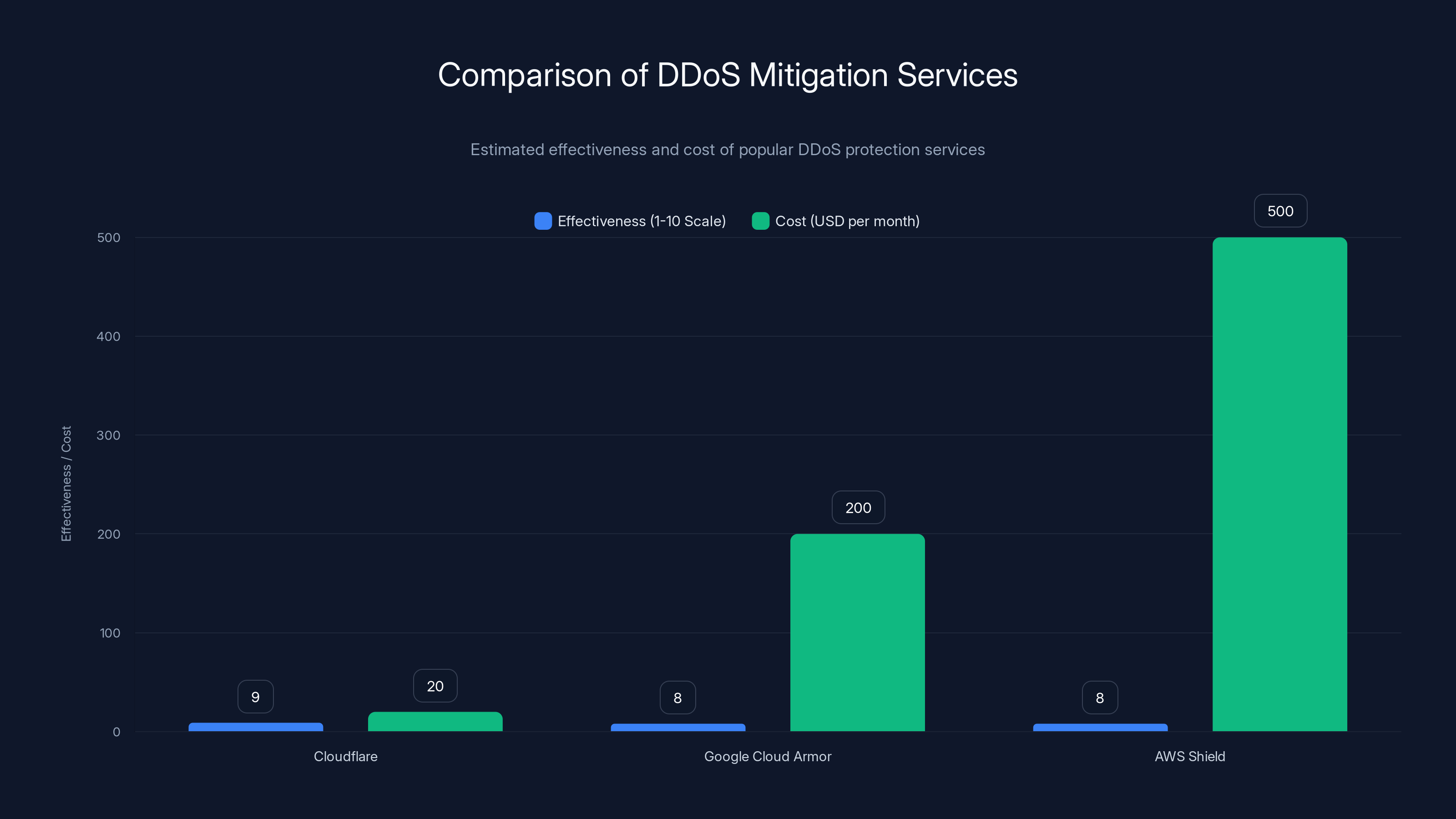
Cloudflare offers high effectiveness at a lower cost compared to Google Cloud Armor and AWS Shield. Estimated data based on typical service offerings.
Understanding DDoS Attack Mechanics
Let's go deeper into how DDoS attacks actually work, because understanding the mechanics helps you defend against them.
Volumetric Attacks
These are the "spray and pray" of DDoS. Attackers flood the target with as much traffic as possible. The goal is simple: use up all available bandwidth so legitimate traffic can't get through.
Common volumetric attacks include:
UDP Floods where attackers send massive volumes of User Datagram Protocol packets. UDP is connectionless, so the target system wastes resources trying to process thousands of packets that have no follow-up communication.
ICMP Floods (Ping floods) where attackers send thousands of ping requests. The target spends CPU resources responding to each ping.
DNS Amplification where attackers send small DNS requests to innocent third-party servers with a spoofed source IP (making it look like the requests came from the target). The third-party servers send large responses back to the target. The attacker uses a small request to generate a much larger response, amplifying the attack.
Bandwidth-saturating attacks are easiest to see because they create obvious traffic volume signatures. This is probably why Cloudflare Radar detected only minor spikes if this was indeed DDoS.
Protocol-Based Attacks
These exploit weaknesses in protocols themselves rather than simply overwhelming bandwidth.
SYN Floods exploit the TCP three-way handshake. An attacker sends thousands of SYN (connection initialization) packets with spoofed IP addresses. The target allocates resources for each connection, waiting for the final handshake step that never comes. Eventually, the connection table fills up and legitimate connection attempts fail.
Fragmented Packet Attacks send packets that are intentionally broken into fragments. Processing these fragments consumes CPU resources, eventually overwhelming the target's ability to handle legitimate requests.
Smurf Attacks where attackers send ICMP echo requests to a broadcast address with the source IP spoofed to be the target's IP. All computers on the network respond, generating hundreds of responses flooding the target.
Protocol-based attacks don't necessarily require massive bandwidth, making them harder to detect with simple traffic volume monitoring.
Application-Layer Attacks
These are the most sophisticated because they exploit business logic rather than network constraints.
HTTP Floods where attackers send what looks like normal HTTP requests, but in such volume that the web server can't keep up. Unlike simple TCP floods, these requests actually make it to the application layer, forcing the server to do real work processing each request.
Slowloris Attacks where attackers establish connections to the web server and send HTTP requests extremely slowly, never completing them. The server keeps connections open, eventually exhausting the maximum number of concurrent connections available. Meanwhile, legitimate users get "Connection Refused" errors.
Cache-Busting Attacks where attackers request different URLs each time to prevent caching. The server has to regenerate content for each request even though a cache would have served most legitimate users instantly.
Database Query Attacks where attackers trigger expensive database queries. A login attempt that validates credentials requires database lookup. If the attacker triggers thousands of invalid login attempts, the database might spend all its resources processing these queries, leaving none for legitimate traffic.
Application-layer attacks look like legitimate traffic, making them exceptionally hard to detect and defend against.

How Organizations Defend Against DDoS Attacks
Now that we understand how attacks work, let's look at how modern organizations defend themselves.
Layer 1: Perimeter Defense
The first line of defense is upstream. Before traffic even reaches your infrastructure, you want filtering happening.
DDoS Mitigation Services like Cloudflare's DDoS protection, Google Cloud Armor, or AWS Shield sit between your servers and the internet. When attack traffic arrives, these services' massive networks absorb it. They detect anomalous patterns and block traffic before it reaches your infrastructure.
How it works: Your DNS points to the mitigation service instead of your servers directly. All traffic flows through their systems. They analyze patterns, block what looks like attack traffic, and forward legitimate traffic to you.
Advantage: They have massive upstream capacity. A 100 gigabit per second DDoS attack that would crush your infrastructure barely registers for them because they're absorbing hundreds of gigabits per second across all customers. Cost: Usually subscription-based, $20-1000+ per month depending on protection level.
ISP-Level Filtering is another layer. Internet Service Providers can implement filters at their backbone. If they detect attack traffic coming from the internet heading to your network, they can block it before it even enters your circuit.
Advantage: Protects your internet connection from saturation. Disadvantage: ISP support varies wildly. Some ISPs have sophisticated DDoS filtering. Others offer nothing.
Layer 2: Network Infrastructure
At your network edge, you want intelligent routing and filtering.
Router ACLs (Access Control Lists) can block traffic from known bad sources or traffic matching attack signatures.
Load Balancers distribute traffic across multiple servers. More importantly, good load balancers can detect and drop malformed traffic, requests from suspicious sources, or traffic patterns indicating attack.
Rate Limiting at the network level caps how many requests any single source can make. If one IP tries to send 10,000 requests per second, the router drops everything after the configured threshold.
Geo IP Filtering blocks traffic from countries where you don't do business. If you're a French bank, you probably don't have customers in North Korea, so blocking traffic from that region reduces attack surface.
Layer 3: Web Application Firewall (WAF)
A WAF sits in front of your web application and inspects every request.
Signature-Based Detection blocks requests matching known attack patterns. For example, if request URL contains <script> or ' OR '1'='1 (SQL injection pattern), it's blocked.
Rate Limiting at Application Layer caps requests per user, session, or IP address.
Behavioral Analysis detects when a user suddenly makes hundreds of requests when they normally make five.
Challenge-Response can require CAPTCHA completion for suspicious traffic, allowing humans through but blocking bots.
Example: A customer tries to log in 3 times with wrong password. They get blocked for 15 minutes. This stops brute force attacks while allowing legitimate users to retry.
Layer 4: Architectural Resilience
Beyond perimeter defenses, architecture matters.
Geographic Distribution means your service runs in multiple data centers across different regions. If attackers target your US data center, your European data center keeps running. Customers fail over to the unaffected region.
Database Optimization prevents expensive queries from locking up under load. Caching layers (Redis, Memcached) serve popular data without hitting the database. Read replicas distribute query load.
Auto-Scaling automatically spins up additional servers when load increases. DDoS attacks cause load to spike. Auto-scaling provisions additional capacity. Attackers need more and more resources to overwhelm you. Eventually, the cost becomes prohibitive for them.
Queue-Based Architecture buffers traffic. Instead of handling every request immediately, requests go into a queue. Background workers process them. If traffic spikes, requests queue up. Workers gradually work through them. System remains available even if response time increases.
Separation of Concerns means attacking one component doesn't take down everything. If the API is under DDoS, the database might still work. If the web interface is attacked, the mobile app continues functioning.

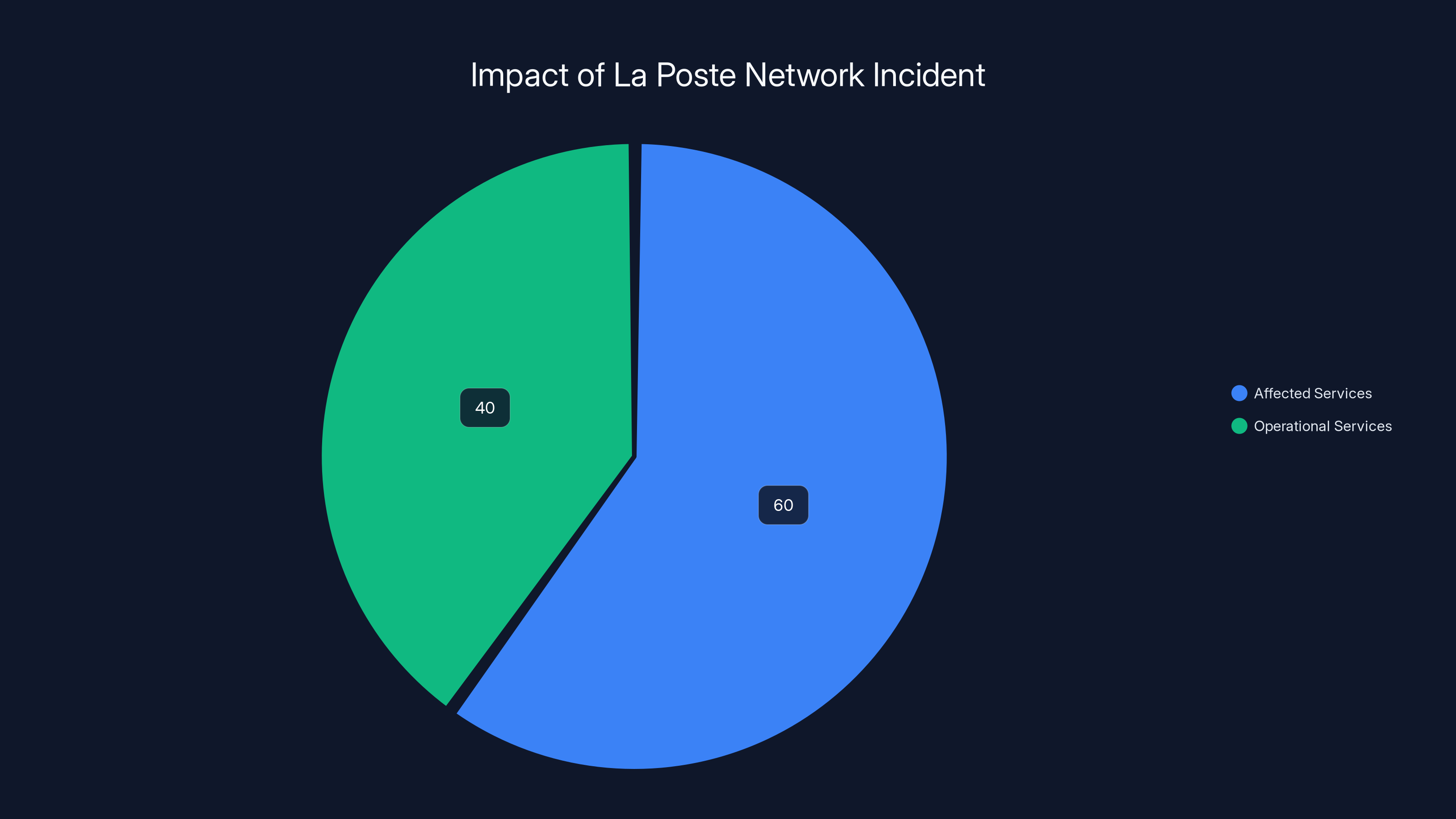
Estimated data shows that approximately 60% of La Poste's digital services were affected, while 40% remained operational, highlighting the selective nature of the incident.
What La Poste Should Have Done (And What You Should Do)
Looking at the La Poste incident, several defensive measures clearly needed strengthening.
Before the Attack: Preparation
Incident Response Plan needs to be documented, regularly tested, and widely understood. Who gets notified? In what order? Who has authority to make decisions? How do we communicate with customers? A good incident response plan is 20+ pages of specific procedures, not a vague "we'll figure it out" approach.
Regular Security Audits by external experts would have likely identified vulnerabilities. Annual audits are standard practice. La Poste should have been conducting penetration testing, vulnerability assessments, and threat modeling regularly.
DDoS Mitigation Service Evaluation should happen before you're attacked. Organizations providing critical services need to contract with DDoS protection providers. This isn't optional.
Redundancy and Failover testing ensures that if primary systems go down, backup systems actually work. It's embarrassing to discover during an incident that your "backup" system doesn't actually work because nobody tested the failover process in years.
Communication Templates prepared in advance mean that when an incident happens, leadership can release statements within minutes, not hours.
Supply Chain Security Program should audit and monitor the security of vendors with access to critical systems. This should include regular security assessments, incident response drills with vendors, and contractual requirements for notification if the vendor is compromised.
During the Attack: Response
Activate Incident Response Team immediately. This is a decision that should take 30 seconds, not 30 minutes. Someone needs authority to declare a critical incident and initiate the response playbook.
Implement Communication Protocol with updates every 30 minutes. Customers need to know: what's happening, what impact they're experiencing, what you're doing, and when you'll update them next. Silence kills trust faster than bad news.
Activate DDoS Mitigation if you're using external services. Redirect DNS, activate failover, trigger protection mechanisms.
Isolate Affected Systems to prevent lateral movement if this is ransomware or other malicious access. Infected systems should be isolated from the network while uncompromised systems continue providing service.
Increase Monitoring and Logging to maximum levels. Every single event should be logged and monitored. You need data to understand what happened.
Coordinate with Law Enforcement and Cybersecurity Agencies if this is a targeted attack. In France, this would mean contacting ANSSI (National Cybersecurity Agency). They have resources and information about known threat actors.
After the Attack: Recovery and Learning
Incident Post-Mortem within 48 hours. What happened? How did we respond? What worked? What failed? What will we change?
Root Cause Analysis to understand why the attack succeeded. Was it a vulnerability in our code? A misconfiguration? A compromised third party? Understanding the root cause prevents recurrence.
Security Improvements implemented immediately. If root cause was a specific vulnerability, patch it. If it was a process failure, change the process. If it was a staffing issue, hire or train more people.
Communication to Customers about what happened and what we're doing to prevent recurrence. Transparency builds trust. Silence erodes it.
Lessons Shared with Industry help others defend against similar attacks. This is why security researchers publish findings. A rising tide lifts all boats.

Critical Infrastructure Security Trends
The La Poste incident sits within larger trends in how critical infrastructure is targeted and defended.
Increasing Attack Sophistication
Attackers are getting smarter. Volume-based DDoS attacks are becoming less common because they're easy to detect and defend against. Sophisticated application-layer attacks that look like legitimate traffic are increasing. Advanced threats use multiple attack vectors simultaneously, forcing defenders to juggle multiple incident response streams.
Convergence of Cybersecurity and Physical Security
Historically, cybersecurity and physical security were separate domains. Now they're merging. A cyberattack on power grid controls could cause physical blackouts. An attack on hospital systems could delay surgeries. This convergence means security teams need broader thinking about cascading failures.
Supply Chain as the Weak Link
Organizations are starting to understand that their security is only as strong as their weakest vendor. This is driving "zero trust" architecture where you assume every vendor, every connection, every system could be compromised. You verify everything.
Regulatory Pressure
Governments are implementing regulations requiring organizations to maintain minimum security standards, report breaches quickly, and conduct regular security assessments. The EU's NIS2 Directive requires critical infrastructure operators to maintain robust cybersecurity. Similar regulations exist in most developed countries.
AI and Automation in Security
Increasingly, security teams are using AI to detect anomalies, predict attacks, and respond to threats automatically. A system can detect an unusual access pattern and block access faster than humans could respond. This is necessary because attack speed is increasing. Human-speed incident response is no longer viable.

The Cost of Downtime
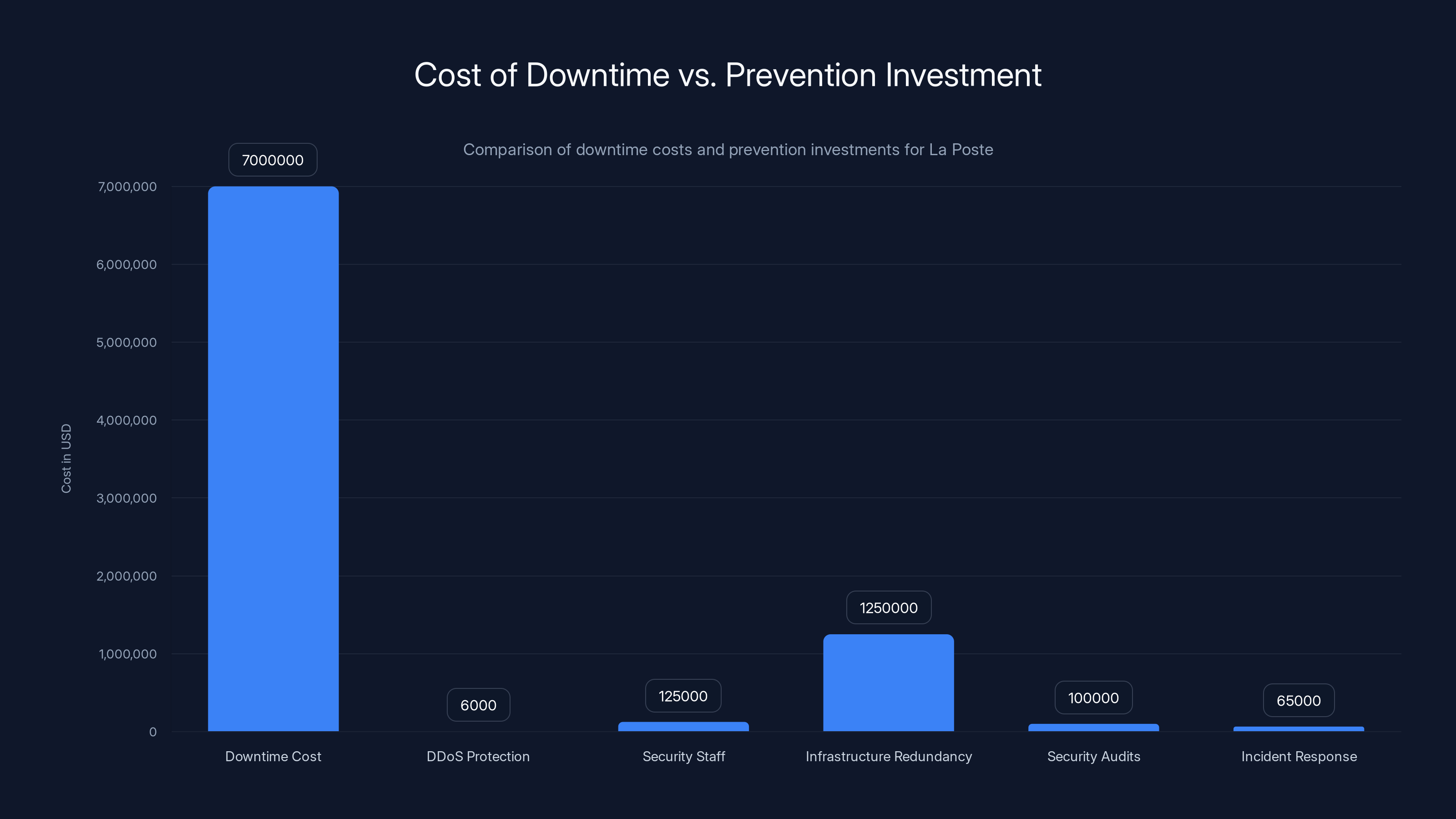
Let's quantify what an outage actually costs an organization like La Poste.
Average cost per minute of downtime for critical services: $5,600 according to Gartner. This includes lost transactions, customer support overhead, productivity loss, reputational damage, and regulatory penalties.
If La Poste's systems were offline for 4 hours (a conservative estimate based on incident reports), that's 240 minutes ×
For a company like La Poste with $28 billion in annual revenue, that's not bankruptcy-level damage. But it's significant. And it's completely preventable through proper security investment.
Better way to think about it: What's the cost of preventing such attacks?
- DDoS protection service: 6,000/year
- Additional security staff: $100,000-150,000/year per person
- Infrastructure redundancy: $500,000-2,000,000 upfront
- Regular security audits: $50,000-150,000/year
- Incident response planning and drills: $30,000-100,000/year
Total investment:

Lessons for Your Organization
Whether you're a Fortune 500 company or a mid-size business, the La Poste incident offers crucial lessons.
Lesson 1: Criticality Demands Investment
If your service is critical to others' operations, security investment is non-negotiable. You're not being paranoid. You're being responsible.
Lesson 2: Transparency Reduces Damage
Communicate during crises. A clear explanation of what happened and what you're doing builds trust. Silence breeds speculation and distrust.
Lesson 3: Plan Before Crisis Hits
Incident response plans need to be written down, tested regularly, and understood by the team. You won't think clearly during an actual incident. You need procedures.
Lesson 4: Third-Party Risk is Real
You're only as secure as your least-secure vendor. Assess vendor security regularly. Include security requirements in vendor contracts. Require notification if they're compromised.
Lesson 5: Defense in Depth Works
No single security measure stops all attacks. Multiple layers of defense—perimeter filtering, WAF, rate limiting, architectural resilience—work together to make attacks progressively more expensive for attackers.
Lesson 6: Monitoring and Visibility Matter
You can't defend what you can't see. Invest in logging, monitoring, and analysis. Know what normal looks like so you can detect anomalies.

The Bigger Picture: Why This Matters Beyond La Poste
The La Poste incident matters because it highlights a fundamental vulnerability in how modern society operates. We've built an increasingly digital infrastructure, but security often lags behind functionality.
Consider the chain of dependencies:
- Citizens use La Poste for banking, communications, and logistics
- Businesses use La Poste to reach customers and process payments
- Government services integrate with La Poste's digital identity
- Each of these sectors depends on others
When one critical node in this network fails, cascading effects propagate through the entire system.
This is why governments now treat cybersecurity as a national security issue. Attacks on critical infrastructure can cause broader societal harm than traditional physical attacks. Disrupting a bank can destabilize financial markets. Disrupting energy infrastructure can cause blackouts that affect hospitals, water treatment, communications.
The La Poste incident, while resolved relatively quickly, demonstrated this vulnerability. And it will happen again. Probably to multiple organizations simultaneously during a coordinated campaign.
The question for every organization: Are you ready?

Implementing DDoS Protection: Practical Steps
If you're responsible for infrastructure, here's what you should actually do, in order of priority.
Step 1: Assess Your Current State (Week 1)
Document your current architecture:
- Where do you host? Cloud (AWS, Azure, GCP) or on-premise?
- What's your current redundancy? Do you have failover systems?
- What monitoring do you have in place? Can you detect attacks?
- What's your incident response process? Do you have a documented plan?
- Who are your critical vendors? What's their security posture?
Honestly assess your readiness: If you were attacked tomorrow, what would you do? If you don't know, that's the starting point.
Step 2: Establish DDoS Baseline (Week 2)
Understand your normal traffic patterns:
- How much traffic do you normally receive?
- What time of day is busiest?
- Which regions send most traffic?
- What does normal server load look like?
- How do users typically access your service?
This baseline is critical for anomaly detection. If you don't know what normal is, you can't identify abnormal.
Step 3: Implement DDoS Monitoring (Week 3)
Set up tools to track traffic and detect anomalies:
- Network monitoring tools that show inbound traffic volume, source IPs, protocol distribution
- Application monitoring that shows request rates, response times, error rates
- Log aggregation that centralizes logs from all systems
- Alert rules that notify you when thresholds are exceeded
Free or open-source options: Prometheus for metrics, Kibana for log analysis, Grafana for visualization.
Paid options: Datadog, Splunk, New Relic.
Step 4: Deploy DDoS Mitigation (Month 1)
For organizations handling critical data or with high availability requirements, contract with a DDoS mitigation service:
- Cloudflare: $200/month for DDoS protection, includes other security features
- AWS Shield Advanced: $3,000/month if on AWS
- Google Cloud Armor: Pay-per-request pricing, usually $75-500/month
- Akamai DDoS: Enterprise pricing, $10,000+/month
For budget-constrained organizations, even basic perimeter firewalls with rate limiting provide some protection.
Step 5: Implement Rate Limiting (Month 1)
At your load balancer and web application:
- Limit requests from single IP: 100 requests/minute
- Limit API calls per authenticated user: 1,000/hour
- Limit login attempts: 5 attempts, then 15-minute lockout
- Limit password reset requests: 3 per hour
- Limit form submissions: throttle based on user behavior
Implementation examples:
Nginx configuration:
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
limit_req zone=mylimit burst=20;
Application code (Node.js example):
javascriptconst rate Limit = require('express-rate-limit');
const limiter = rate Limit({
window Ms: 60 * 1000, // 1 minute
max: 100 // 100 requests per minute
});
app.use('/api/', limiter);
Step 6: Redundancy and Failover (Month 2-3)
Ensure critical systems have backup:
- Database replication to secondary location
- DNS failover to backup servers
- Traffic routing that automatically shifts to healthy servers
- Regular failover drills (monthly) to ensure backup actually works
Step 7: Incident Response Plan (Month 2)
Document your response:
- Detection: How do we know we're under attack? What alerts trigger incident response?
- Notification: Who gets called first? In what order?
- Communication: Who is authorized to speak to media? Customers? What channels?
- Investigation: Who investigates? What tools do they use? Where are logs stored?
- Mitigation: What steps do we take to stop the attack? In what order?
- Recovery: How do we bring systems back online? How do we verify everything is working?
- Post-Incident: How do we analyze what happened? What changes do we make?
Document this plan. Print it. Give copies to key people. Practice it annually.
Step 8: Communication Strategy (Month 2)
Develop message templates for use during incidents:
Customer update template:
"We identified unusual network activity affecting our online services at [TIME]. Our incident response team has been activated and is investigating. We expect to provide an update within [TIMEFRAME]. Current status: [affected services]. Workarounds: [alternative methods]. Thank you for your patience."
Media statement template:
"[Company] can confirm we experienced a service disruption this morning. We have activated our incident response procedures and are working with [law enforcement/cybersecurity experts] to investigate. The safety and security of our customers' data remains our highest priority. We will provide additional information as it becomes available."
Prepare these templates in advance. Have legal and PR review them. This allows you to communicate clearly within minutes of an incident rather than hours.

FAQ
What is a DDoS attack?
A Distributed Denial of Service attack floods a target system with traffic from many sources simultaneously, overwhelming its capacity to process legitimate requests. Unlike a cyberattack that steals data, DDoS attacks make services unavailable. They work by consuming bandwidth, server resources, or exploiting protocol weaknesses to crash services.
How does a DDoS attack work?
Attackers coordinate traffic from many sources (often compromised computers called "botnets") to send requests to a target. The target's servers spend all their resources processing these malicious requests and have none left for legitimate users. It's like a storefront suddenly flooded with thousands of people blocking the entrance, preventing real customers from getting in. The attack terminates when the attacker stops sending traffic or the target implements blocking measures.
What are the main types of DDoS attacks?
There are three categories: volumetric attacks (flood with massive traffic volume), protocol attacks (exploit weaknesses in network protocols), and application-layer attacks (appear as legitimate traffic but exploit business logic). Application-layer attacks are the most sophisticated because they're hardest to detect.
How can I detect if I'm under DDoS attack?
Watch for sudden increases in traffic volume from multiple sources, unusual patterns in request origins, increased error rates on your servers, and spikes in CPU or memory usage. Network monitoring tools can alert you automatically when traffic exceeds thresholds. Application logs showing repeated failed requests from diverse sources is another indicator.
What's the difference between DDoS and ransomware?
DDoS makes services unavailable through overwhelming traffic. Ransomware is malware that encrypts your data and demands payment for decryption. DDoS is a denial-of-service attack. Ransomware is a theft-extortion attack. They're completely different threats requiring different defenses.
How much does DDoS protection cost?
Basic DDoS protection services start at
Can I prevent DDoS attacks completely?
No single solution stops all DDoS attacks. Instead, implement defense-in-depth: upstream DDoS mitigation services, network-level filtering, application-level rate limiting, and architectural resilience. Good defense makes attacks progressively more expensive, eventually reaching a point where attackers move to easier targets.
What should I do if I'm currently under DDoS attack?
First, activate your incident response plan. Notify your DDoS mitigation service if you have one. Increase monitoring and logging. Implement rate limiting if not already active. Contact your ISP and hosting provider. Prepare customer communications about the situation. Coordinate with law enforcement if appropriate. Don't panic. Most DDoS attacks last hours or days, not weeks.
How do I test if my DDoS protection actually works?
Conduct a controlled load test with your DDoS mitigation provider's involvement. They can send simulated attack traffic to verify your systems respond correctly. Never conduct unauthorized penetration testing on networks you don't own. Regular failover drills (at least monthly) ensure your backup systems actually work.
What's the role of government in DDoS response?
In France, the ANSSI (National Cybersecurity Agency) coordinates national response to major cyberattacks. Most countries have similar agencies. Law enforcement can investigate crimes. Incident response is typically a private-sector responsibility, but government resources can help with attribution, threat intelligence, and coordination.

Conclusion: Building Resilience
The La Poste incident wasn't exceptional in its technical sophistication. DDoS attacks are relatively common. What made it significant was that it targeted critical infrastructure supporting millions of people and exposed gaps in how the organization responded.
For security professionals, IT directors, and business leaders, the lessons are clear: critical infrastructure demands serious security investment. Not as a checkbox compliance exercise, but as a core operational responsibility.
Resilience requires three things:
First, technical defenses. Implement DDoS mitigation, redundancy, monitoring, and architectural resilience. These are the tools and infrastructure that actually prevent or minimize attacks.
Second, operational readiness. Have incident response plans tested regularly. Ensure critical staff understand their roles. Establish communication protocols. Practice the response until it becomes muscle memory.
Third, organizational culture. Security can't be an afterthought or a compliance burden. It needs to be embedded in how decisions are made, investments are prioritized, and vendors are selected. When security competes for budget against feature development, security loses. That needs to change for critical infrastructure.
The next major DDoS attack will happen. Maybe tomorrow, maybe next year. The question isn't whether your organization will be targeted. The question is whether you'll be ready.
Start now. Assess your current state. Identify gaps. Prioritize improvements. Implement defenses. Test them. Train your team. Practice responses. Build redundancy.
Do this, and when attacks come, you'll be different from La Poste. You won't be caught unprepared. You won't be silent during crisis. You won't leave customers wondering what's happening.
You'll respond with confidence, recover quickly, and emerge from the incident stronger and more resilient.
That's what security investment actually delivers: resilience. The confidence that you can withstand attacks and keep serving your customers.

Key Takeaways
- La Poste's infrastructure outage demonstrates how critical systems can be taken offline through coordinated attacks, with banking and postal services impacted across millions of users
- DDoS attacks range from simple volumetric floods to sophisticated application-layer attacks that appear legitimate, requiring multi-layered defense strategies
- Defense-in-depth combining upstream mitigation, network filtering, WAF, rate limiting, and architectural redundancy makes attacks progressively more expensive and less attractive to attackers
- Clear incident communication within minutes of detection reduces panic and trust erosion, while silence breeds speculation and organizational credibility loss
- Organizations should invest 1-3% of annual revenue in security measures, which is typically far less than the cost of a single major outage affecting critical services
Related Articles
- Spartacus: House of Ashur Episode 5 Release Date & Time [2025]
- Tell Me Lies Season 3: Release Date, Cast & Plot Updates [2025]
- Air Fryer Christmas Foods: Honest Taste Tests [2025]
- ESET Antivirus 30% Off: Complete 2025 Security Guide [Save $41.99]
- Corsair VANGUARD PRO 96 Hall Effect Gaming Keyboard [2025]
- Google Pixel's Strategy Problem: Why Power and Parity Matter in 2026

